How to use and install FreeOCR languages
Free OCR uses the latest Google Tesseract OCR engine so you can install any language that this engine supports.
FreeOCR includes the following languages by default
| Eng - English Dan - Danish Deu - German Fin - Finnish Fra - French Ita - Italian Nld - Dutch Nor - Norway Pol - Polish Spa - Spanish Swe - Swedish |
to use simply select the 3 digit language code in the toolbar before OCR'ing. If you need additional languages then follow the instructions below. |
How to download and install additional languages
Visit the Tesseract download page and download your chosen language pack
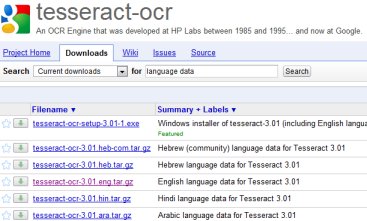
Make sure the language file is for Tesseract 3.00 or higher (the 2.00 files will not work)
After downloading you will need to uncompress the file, we use 7 Zip but WinRar or similar programs will work.
You should end up with a file starting with the 3 digit country and ending with .traineddata
Tesseract uses the ISO 3 letter country codes, more info here
Now open the data folder for Tesseract.
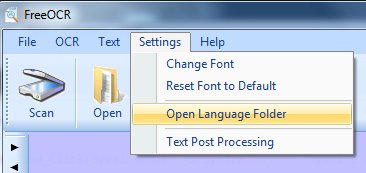
The data folder will open in Windows explorer. Now just Drag & Drop the language data file into the tessdata folder.
Now if you close and reopen FreeOCR it will see the new language file and you can choose it before starting OCR
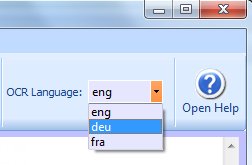
If your OCR language does not exist and you would like to train the engine for a new language then the Tesseract project can be found here: http://code.google.com/p/tesseract-ocr/